


The industry doesn’t have an execution problem; it has a signal problem
For too many companies, test automation hasn’t delivered the promised outcomes at the required release cadence. Results vary widely across organizations, teams, tools, and titles. Everyone is struggling more than most people seem to realize, and problems get misdiagnosed so the wrong solutions are attempted. The reality is that practitioners are not getting the information they need to understand the state of the system, which prevents problems from being fixed.
Signal → Understanding → Resolution → Value
Note: This piece does not prescribe specific solutions; the goal is to identify the problem. We can’t solve what we don’t recognize.
A strong signal means that tests fail only for real problems and each failure clearly identifies why. Only with this understanding can the bugs be fixed and negative user experiences avoided. This fundamental requirement predates the current AI arguments, and exists regardless of tooling and framework choices.
The Pass Rates
Sauce Labs published this data in 2019 (the numbers haven’t changed much since this first report), and it is surprising that it hasn’t prompted more conversations and introspection:
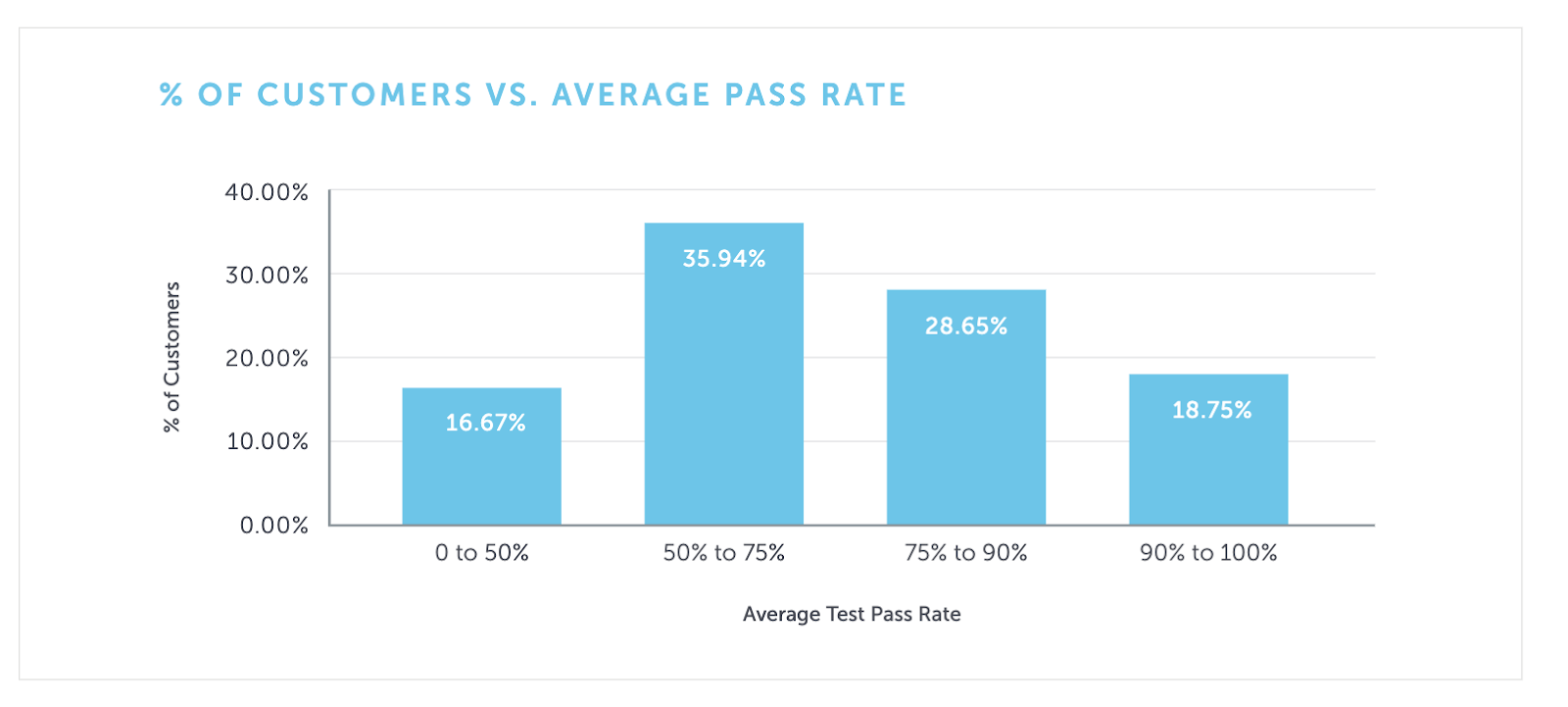
There are confounding factors, but this data suggests that as many as 3 in 4 organizations have insufficient signal for practitioners to understand their test results.
There are only two possible options:
- Delay releases for lengthy investigations
- Ignore test failures when it is time to release
If a test fails in CI and no one is around to investigate it, does quality improve?
Practices like automatic retries, self-healing, and single-platform smoke tests can give the appearance of improved signal, but in reality they merely reduce the gain and hide important information. This creates a significant disconnect between planned coverage and actual understanding of the state of the system. Much of the conversation on this topic focuses on test flakiness, as if intermittent failures are the root cause. Flakiness is mostly a synchronization problem, which is only one of a dozen reasons that tests can fail when the system is working as intended. Even if flakiness were solved, teams would still be drowning in failures.
Missing the Point
The industry is focused on authoring and execution while the real constraint is evaluation and resolution. Test automation has six stages: planning → authoring → orchestrating → executing → evaluating → resolving, and there is no value until all stages are complete. Practitioners spend significantly more time on the last two than the first four. With any template or framework, writing “a” test is easy; writing a test that produces actionable information over time is hard. Most authoring tools are still focused on creation and not actionable information. Similarly, execution time matters, but rarely should it be the priority.
A customer once asked me to reduce their test execution time by 50%. I reviewed their logs and was confident I could do it, but when I asked about their pass rate, they said it was 30%. It made no sense to get this information a few hours sooner if it would take days (if ever) to understand what the failures meant.
It isn’t obvious where the disconnect exists within the company, or who recognizes the limitations of the results that get displayed. The test suite hasn’t finished until every failure is understood. Dashboards look greener than reality because shortcuts must be taken to show marginal value.
During an all-day customer visit with a client, the managers and executives focused their questions on roadmaps and new features. I pulled up the data from the teams in the room and found pass rates under 20% across the board. Tests run on the new version would be as useless as the tests run on the current version. Presumably the practitioners recognize the problem. For these events, I always tried to insert my triage and failure prevention talks into the agenda. Those were always the talks the practitioners thanked me for at the end.
When organizations optimize for the wrong problem, they make decisions that don’t improve understanding.
The Blame Game
When companies don’t understand why they aren’t getting the timely information they need, they fix the wrong things.
It must be Selenium’s fault! “We just need to throw it out and start over with
TestCafe, Puppeteer, Cypress, Playwright, Low Code, AI?”
There are valid reasons for picking any one tool over another,
but the tool choice will not fix the underlying issue.
If a site is in active development, any unattended suite will decay and demand reinvestment,
regardless of framework.
It must be the testers’ fault! “We just need to get rid of testing as an independent role and let the developers do it the right way.” Developers are often more skilled at writing code, but they rarely have the time and incentives to find the problems they created, or learn common testing pitfalls, let alone spend hours (or days) digging through the failures and fixing test code. This form of “shifting left” has only made the signal worse.
My local cadre of testers in Austin were early proponents of “developers should own testing.” When Angie Jones published an article on not letting devs be in charge of testing, I was disappointed that my friends dismissed the conclusion without addressing her reasoning. Good ideas still fail without good implementation. What I’ve seen so far is more component and acceptance tests, but fewer full-stack regression tests. That can produce a stronger signal, but only with a dramatic loss of coverage.
It must be the code’s fault! “We just need to make the tests easier to write with Behavior Driven Development tools.” BDD has a great sales pitch, but between the way it encourages users to write imperative tests and the amount of overhead, it makes test maintenance substantively harder, which significantly reduces the signal.
This mistake has been made before.
History Repeats Itself
When organizations move from human testing to automated testing, they typically start by treating automation like “a faster human who works nights and weekends.” That approach doesn’t scale. A new process with the same objective requires different optimizations. For example, Sauce Labs recommends executing at scale by running atomic, autonomous, short tests. Instead of a few long journeys through the application, like a human tester would do, split tests into independent, focused sessions with specific assertions and code abstractions. It won’t provide the same kind of information a human would, but it can provide more information in less time. That density only helps if the signal is strong.
Similarly, the industry keeps trying to invent a faster automated tester (who also works nights and weekends). This isn’t just about AI; it’s fundamentally the purpose of record and playback tools and deterministic low code solutions. These tools focus on test creation more than understanding the state of the system. There is a sentiment that when tests can be created quickly, the fix for maintainability is just rewriting the test when it fails. This implicitly assumes that all failures are false failures, which short-circuits understanding, and makes the signal worse. These tools need to focus on quickly finding more signal within the noise by identifying when failures are real and surfacing the reason.
One of my main takeaways from my time at Sauce Labs is that good test frameworks are rare and writing them is hard. My solution to this has been to give training, and over the years I’ve given numerous talks and taught multiple workshops on how to create maintainable test suites that quickly surface actionable information. I wish this training scaled to the magnitude of the problem.
Value through understanding
Automation was adopted to keep pace with faster delivery, but outcomes lag when results don’t provide actionable information. While test automation can deliver the understanding needed for release decisions, in practice it often doesn’t. When a process frequently fails to achieve its intended purpose, it must be scrutinized. Optimize for signal first so understanding and resolution happen fast enough to matter. Strategies that hide information don’t improve the signal.
This isn’t a call to replace your existing tools or reorganize your teams. Every framework can be tuned to provide better signal. Each failure needs to explain itself better, and that comes from intentional test design, not specific tooling. AI has the potential to improve this, but it is only as good as the quality of data it’s provided (GIGO - garbage in garbage out).
Testing creates value only when it prevents bad user experiences
- You can’t prevent bad experiences without fixing real bugs
- You can’t fix bugs you can’t find
- You can’t find what your process hides
A strong signal quickly surfaces actionable information from test failures so you can fix real bugs and be confident in the value you’re delivering at scale.
If you enjoyed this, follow me on LinkedIn or send me a message.